In this article
DevOps for software development: what elite teams do right
Tech & Infrastructure
Apr 30, 2026
10 min read
Unlock efficiency with our DevOps for software development guide. Learn essential practices to enhance your team’s workflow and boost deployment speed!

TL;DR:
- Elite DevOps teams deploy 208 times more often with lead times 6,570 times faster than peers.
- DevOps is a practical philosophy any startup can adopt to increase speed and stability.
- Focus on simple, scalable practices like CI/CD, monitoring, and small-tooling before overengineering.
Elite DevOps teams deploy 208 times more frequently than their peers, with lead times that are 6,570 times faster. If that sounds like something reserved for tech giants with armies of engineers, think again. That’s a common misconception worth addressing directly. DevOps is not a luxury for large enterprises, nor is it a single tool you install. It’s a philosophy, a set of working practices that any startup or growing product team can adopt, gradually and practically. This guide will walk you through what DevOps actually means, which methodologies matter most, how to build a workflow that fits your team’s reality, and how to measure real progress using proven metrics.
Key Takeaways
| Point | Details |
|---|---|
| DevOps accelerates results | Teams using DevOps can deploy faster and increase product quality with less downtime. |
| Lightweight workflows win | Startups achieve more by prioritizing simple CI/CD, containers, and monitoring before scaling complexity. |
| Measure to optimize | Use DORA metrics to track performance, spot bottlenecks, and continuously improve. |
| Avoid overengineering | Complex architectures slow startups. Focus on what directly delivers value and iterate quickly. |
What is DevOps and why it matters for startups
Building software fast enough to stay competitive, while keeping it stable enough for users to trust, is one of the defining challenges for any startup. Too many teams treat speed and reliability as opposites, choosing one at the cost of the other. DevOps exists to dissolve that trade-off.
At its core, DevOps is a culture and practice that bridges the gap between software development and IT operations. Instead of developers writing code in isolation and then “throwing it over the wall” to ops teams to deploy and maintain, DevOps encourages both sides to work together throughout the entire software lifecycle. The result is faster feedback, fewer surprises at deployment, and a team that collectively owns the health of the product.
For startups specifically, this matters more than people realize. When your engineering team is small and your runway is finite, every delay in shipping a feature, every hour spent manually deploying code, and every incident that goes unnoticed for hours costs real money and real opportunity. DevOps directly addresses those costs.
The core mechanics of DevOps include CI/CD pipelines, Infrastructure as Code (IaC), containerization, monitoring, and automated testing integrated into development workflows. Each of these practices targets a specific kind of friction that slows teams down.
Let’s be concrete about what each one does:
- CI/CD pipelines (Continuous Integration and Continuous Delivery or Deployment) automate the process of merging code, running tests, and pushing changes to production. Instead of manual releases that happen once a week, code can ship multiple times a day.
- Infrastructure as Code (IaC) treats your cloud infrastructure (servers, databases, networking) as code that can be version-controlled, reviewed, and replicated. Tools like Terraform or Pulumi let you spin up identical environments in minutes.
- Containerization using Docker packages your app and its dependencies together so it runs the same way in development, staging, and production. No more “it works on my machine” problems.
- Monitoring and observability tools like Sentry, Datadog, or UptimeRobot give you real-time visibility into what your application is doing, so you catch issues before your users do.
- Automated testing ensures every code change is validated before it reaches production, reducing the risk of regressions and building confidence in the team.
“DevOps isn’t about tools. It’s about removing friction from the path between an idea and a working feature in production.”
For a startup, adopting these practices doesn’t mean doing everything at once. It means being deliberate about where friction lives and addressing it step by step. See Meduzzen’s startup DevOps services if you want to see how experienced engineers approach this incrementally for growing teams.
The cultural side of DevOps is equally important. Shared responsibility for the product’s health, psychological safety to report problems without blame, and a habit of learning from incidents rather than hiding them, these are the invisible foundations that make the technical practices stick.
DevOps methodologies: Core approaches and best practices
Now that you understand DevOps fundamentals, let’s see the key methodologies and how they translate into best practices for your team. Knowing the principles is one thing; knowing which method to use and when is where real clarity lives.

Continuous Integration is the practice of merging every developer’s code into a shared repository frequently, often multiple times a day. Each merge triggers an automated build and test suite. The goal is simple: catch conflicts and bugs early, when they’re small and cheap to fix, rather than discovering them during a high-stakes release. For startups using GitHub, GitHub Actions makes this straightforward to set up within a single afternoon.
Continuous Delivery vs. Continuous Deployment is a distinction worth understanding. Continuous Delivery means your code is always in a deployable state, but a human still approves the final push to production. Continuous Deployment removes that human gate entirely, and every passing build goes live automatically. For early-stage startups, Continuous Delivery is often the safer starting point, giving the team confidence before switching to fully automated deployments.
Shift-left security, also called DevSecOps, means integrating security checks into the development process from the start rather than auditing the code at the end. This includes things like automated vulnerability scanning, dependency checks (tools like Snyk or Dependabot), and secret scanning to prevent API keys from leaking into public repositories. Addressing security concerns early in development is dramatically cheaper and less disruptive than patching production systems after the fact.
Trunk-based development is a branching strategy where all developers work on short-lived branches and merge back into a single main branch (the “trunk”) frequently, often daily. This contrasts with long-lived feature branches that diverge for weeks and create painful merge conflicts. Paired with feature flags (toggles that let you deploy code without activating it for users), trunk-based development lets you ship continuously while still controlling what users actually see. This is particularly powerful for startups validating features with a subset of users before full rollout.
Here’s a quick comparison of key methodologies to help you orient your team:
| Methodology | Core goal | Best for | Key tool |
|---|---|---|---|
| Continuous Integration | Catch bugs early with automated builds | All team sizes | GitHub Actions, CircleCI |
| Continuous Delivery | Always have a deployable build | Early-stage startups | GitHub Actions, ArgoCD |
| Continuous Deployment | Ship every passing build automatically | Mature pipelines | Spinnaker, Flux |
| Trunk-based development | Reduce merge conflicts, ship faster | Teams of 2+ engineers | Git, LaunchDarkly |
| DevSecOps | Embed security in every step | All stages | Snyk, Dependabot, Trivy |
| Feature flags | Decouple deploy from release | Product experiments | LaunchDarkly, Unleash |
For a deeper look at how these methodologies fit into the broader startup journey, the startup software development guide on Meduzzen’s blog walks through the full product lifecycle. And if your startup is building a SaaS product, the lens of scalable SaaS development will help you see how these practices compound over time.
Pro Tip: Don’t try to implement all of these methodologies simultaneously. Start with CI (the fastest win), add monitoring, then layer in Continuous Delivery and feature flags as your team’s confidence grows.
One thing that often gets overlooked is the team dimension of methodology choice. Trunk-based development requires trust and communication. If your team isn’t yet in the habit of syncing regularly, merging to trunk daily can feel chaotic. Build the habit before enforcing the process.
Building a startup-ready DevOps workflow: Tools and strategies
With best practices in mind, here’s how to build a DevOps workflow tailored for startup realities, including tool choices and practical strategies. The key word is “tailored.” What works for a 500-person engineering org will sink a 5-person startup. Constraint, in this context, sharpens creativity.
For most early-stage teams, the right starting tools are version control with Git, CI/CD with GitHub Actions, and monitoring with Sentry or UptimeRobot. These tools are low-cost, well-documented, and fast to set up. Only introduce Infrastructure as Code after you’ve achieved product-market fit (PMF). And avoid Kubernetes until you’re managing 10 or more services. Using Kubernetes for a two-service app is like hiring a full-time logistics coordinator to manage your own grocery runs.
Here’s a practical seven-step DevOps workflow designed for startup realities:
| Step | Practice | Tool recommendation |
|---|---|---|
| 1 | Set up version control with branching strategy | Git, GitHub |
| 2 | Implement basic monitoring and alerting | Sentry, UptimeRobot |
| 3 | Document and test incident response plans | Runbooks, PagerDuty (Lite) |
| 4 | Automate CI pipeline (build + test on every PR) | GitHub Actions |
| 5 | Introduce Infrastructure as Code | Terraform or Pulumi |
| 6 | Containerize your services | Docker, Docker Compose |
| 7 | Establish feedback loops (retrospectives, metrics reviews) | Weekly team rituals |
The sequence matters. Monitoring before IaC, and IaC before containers. Many teams jump straight to Docker and Kubernetes, then realize they have no idea what’s happening inside their systems because they skipped monitoring. That’s building stability out of chaos without a flashlight.
Here are common startup pitfalls and how to avoid them:
- Skipping rollback testing. Always test that your deployment can be rolled back cleanly before you depend on it in production. A deploy that can’t be undone is a liability.
- Inconsistent environments. Without IaC, your staging environment will drift from production over time, causing bugs that are impossible to reproduce locally.
- Secrets in plain text. Use a secret manager (AWS Secrets Manager, HashiCorp Vault) from day one. Secret scanning in CI pipelines catches accidental leaks before they reach your repository’s history.
- Overengineering early. This is the most expensive mistake. Overengineering kills velocity in teams with fewer than 50 engineers. A complex microservices architecture built before you’ve validated your product is technical debt that will slow every feature you try to ship.
“The goal is not the most sophisticated DevOps stack. The goal is the simplest stack that lets you ship reliably, learn quickly, and sleep soundly.”
For teams ready to go deeper on workflow design, Meduzzen’s posts on scalable workflow tips and the engineering scaling checklist provide hands-on guidance for each growth stage. If you need custom support, see custom DevOps support from engineers who’ve done this across dozens of startup environments.
Pro Tip: Use Docker Compose for local development and early staging environments. It gives you the benefits of containerization without the operational overhead of Kubernetes. Upgrade when the complexity genuinely demands it, not before.
The most underappreciated element of a startup DevOps workflow is the feedback loop, specifically the human one. Technical monitoring tells you when something breaks. Team retrospectives tell you why it keeps breaking. Both are essential.
Measuring success: DORA metrics and real-world DevOps impact
Once your workflow is in place, it’s time to track results. Here’s how to measure DevOps performance, and what to expect based on real data.
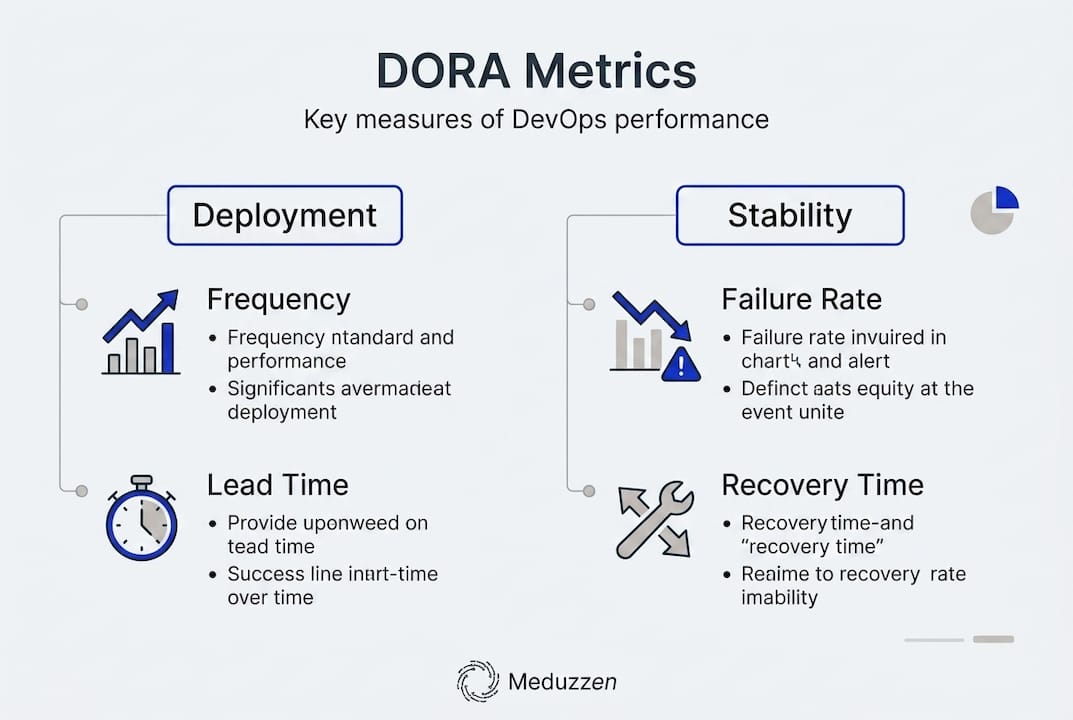
DORA metrics (developed by the DevOps Research and Assessment team at Google) are the industry standard for measuring software delivery performance. There are four core metrics, and every startup team should know them:
- Deployment frequency: How often you deploy to production. Elite teams deploy multiple times per day, a rate 208 times more frequent than low-performing teams.
- Lead time for changes: The time from a code commit to that code running in production. Elite teams achieve lead times under one day, compared to months for low performers (6,570 times faster).
- Change failure rate: The percentage of deployments that cause a production incident requiring a hotfix or rollback. Elite teams stay within the 0 to 15% range.
- Mean time to recovery (MTTR): How quickly you can restore service after an incident. Elite teams recover in under one hour.
These aren’t aspirational benchmarks for billion-dollar companies. They’re achievable realities for startups that invest in the right practices early. Elite teams are twice as likely to exceed their organizational performance goals compared to low performers.
Tracking these four numbers gives your team a clear, honest picture of where you are and what to improve. Low deployment frequency? Your CI/CD pipeline or code review process has bottlenecks. High change failure rate? Your test coverage needs work. Long recovery times? You need better monitoring and incident runbooks.
AI-powered tools are accelerating DevOps outcomes in measurable ways. A GitHub AI-powered DevOps tools like the Copilot case study with a 500-engineer organization showed a 32% increase in pull requests per developer per week, a 26% reduction in cycle time, a 26% increase in features shipped, and a 10% reduction in bug rate after adoption. These are real numbers from a real team, and the trend is consistent across many organizations.
For smaller teams, even a modest AI coding assistant can compress the time between writing code and having it reviewed, tested, and shipped. The compounding effect over weeks and months is significant.
32% more PRs per developer per week. 26% fewer bugs. These are the gains of thoughtful automation.
To start tracking DORA metrics for your team, you don’t need complex tooling. A simple spreadsheet with weekly entries for deployment count, last week’s cycle time, recent incident count, and average recovery time is enough to get started. Over time, you can integrate tools like LinearB, Jellyfish, or Sleuth to automate the tracking.
The full cycle development guide provides a practical framework for thinking about your entire pipeline from idea to production, and modern engineering practices covers how to build the team habits that make these metrics improve over time.
What most DevOps guides miss for startups
As you move from measurement to optimization, consider what’s often overlooked in conventional DevOps advice.
Most DevOps content you’ll find online is written for teams that already have scale. They assume you have dedicated platform engineers, a security team, and the luxury of time to build elaborate infrastructure. For early-stage startups, following that advice uncritically is a trap.
The real insight is this: the companies that win at DevOps early are not the ones with the most sophisticated stacks. They’re the ones who automate CI/CD on day one, monitor early, use Docker Compose over Kubernetes at the start, track DORA metrics from the beginning, and foster high collaboration without building full cross-functional structures before they’re needed.
Lightweight wins. Every time. The teams we’ve worked with that struggled the most were not the ones who built too little. They were the ones who built too much, too soon, and spent months maintaining infrastructure instead of shipping product.
There’s another thing guides rarely mention: the value of monitoring as a cultural act. When your team reviews production metrics together every week, something shifts. Engineers start caring about the behavior of their code in the real world, not just whether it passed the test suite. That behavioral shift, that sense of shared ownership, is worth more than any specific tool choice.
Pro Tip: If you’re unsure where to start with DevOps for your Python-based startup, the Python for startup DevOps guide covers practical tooling choices that fit small teams without introducing unnecessary complexity.
DevOps done right doesn’t feel like a process. It feels like trust. Trust that the code you write will get to users quickly, reliably, and without drama.
Scale your product with expert DevOps teams
Knowing the path is one thing. Walking it with the right people is another.
At Meduzzen, we work with startups and product teams at every stage. If Python powers your stack, our Python engineers plug directly into your DevOps workflow from day one. We operate at every stage of DevOps maturity, from setting up a first CI/CD pipeline to designing resilient, cloud-native architectures that scale. Our pre-vetted engineers integrate directly into your team, bringing practical experience across Python, cloud infrastructure, and modern DevOps tooling. Whether you need custom DevOps services to build your pipeline from scratch, web development services to accelerate your product, or staff augmentation for startups to grow your engineering capacity without the overhead of full-time hiring, we make the transition practical and predictable. Let’s build something that ships reliably.
Frequently asked questions
What are the first DevOps practices a startup should implement?
Startups should prioritize version control, CI/CD, and monitoring first, using Git, GitHub Actions, and tools like Sentry or UptimeRobot, followed by containers once the basics are stable.
How do DORA metrics help teams improve performance?
DORA metrics track deployment frequency, lead time, change failure rate, and recovery time, giving teams a concrete signal of where their pipeline has bottlenecks, based on elite performance benchmarks like sub-one-hour recovery.
Should small teams use Kubernetes for container orchestration?
For teams with fewer than 10 services, Docker Compose is simpler and avoids the configuration and maintenance overhead that Kubernetes introduces at small scale.
How does AI, like GitHub Copilot, impact DevOps workflows?
GitHub Copilot drove measurable productivity gains in a 500-engineer organization, including 32% more pull requests per developer and a 26% faster cycle time, making it a practical addition for any team.
What’s the main risk for startups implementing DevOps?
Overengineering too early is the most common and costly mistake, as excess complexity kills velocity in teams under 50 engineers, making lightweight, scalable practices the safer and faster path.